I have several hammers, so everything is a nail.
I wanted to be able to remember the sermons I heard on Sunday better throughout the week. Whenever I would recall the sermon on my own, eventually I could remember the structure and the main points, but late in the week or even months later it can be hard to recall the structure and points.
I’ve been using AI a lot more in many areas of life and it has really been helpful for me when I use it for summaries of things I’ve already read. That’s when I had the idea to have an AI generated summary of the main sermon points and the application points presented in the sermon. I could read the summary which would help my own memory solidify what I had already heard.
I also realized that I was probably not the only person who might want to have these summaries, and so to bring the idea to life and personally remove all barriers to reading such a summary regularly, I knew I would need to automate the whole process otherwise I would probably not always do it.
Alright, let’s get out the first hammer:
Browser Automation
North Hills Church (the Church I attend) posts their sermons with a lot of helpful resources. A big thank you to the people who lovingly add the sermon videos, audio transcript, slides, etc to their website for accessing.
This was my starting point then, I would use the power of automating a web browser to grab what I needed to pull this off.
This was a perfect excuse to learn Puppeteer to get the data I needed.
The puppeteer script I wrote simply navigates to the sermons page of the website, clicks the first sermon link, and scrapes the needed information off of the page such as:
- Transcript (if available)
- Audio download link (used when no transcript is up yet)
- Sermon title
- Preacher
- Date
- Etc.
The script then sends a POST request to a self-hosted automation platform I have been using a lot lately called n8n.io. The POST request contains all of the data we scraped from the North Hills Church website.
This is where the real magic happens.
Sermon Summary Webhook
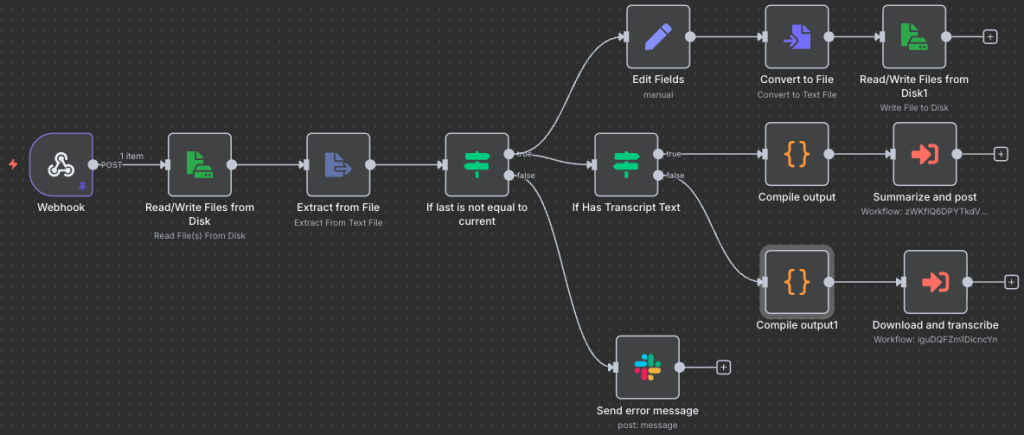
Breaking this down, there’s a first logical thing I want to do: ensure at a minimum that the data we are processing was not the last link that we processed (so we don’t keep duplicating posts over and over). I check a text file that contains the last sermon page link we processed. If it’s the same I just notify myself via Slack for awareness. If we’re looking at a different link, it’s time to do some work.
There’s the top 3 nodes that just write this new link to that file to guard against duplicates in the future, and then another IF block. I found that North Hills eventually makes a transcription available on the page, but it is not done immediately (but seriously, whoever does those transcriptions, thank you!). In the event we’re looking at a page with a transcription, we can move on to the workflow “Summarize and post”, but if we don’t have transcription data then we will have to make one from the mp3 file that North Hills provides 🙂
Download and Transcribe
Let’s look at “Download and transcribe” next:
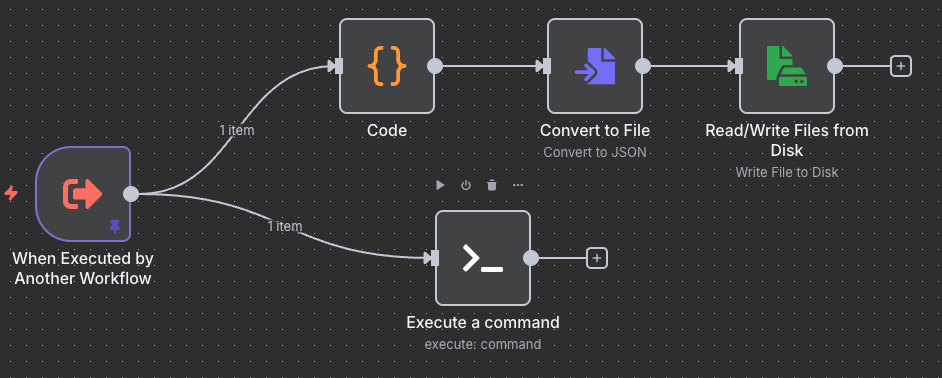
A very simple workflow that will first (along the top) save all of the other collected data (sermon title, teacher, etc) to a .json file to be used at the end and saves it for use later. The bottom “execute a command” remotely logs in to my Mac Mini server and downloads the mp3 file to a very specific folder for a Mac App called “Whisper Transcription” to pick up. This app is constantly watching the folder for any mp3 files, and if it finds any it will automatically do a speech to text transcription. It outputs the transcription in .txt format in the same folder as the mp3 was found.
This means we can either use the transcript provided by North Hills OR we can create our own on demand from the mp3 file provided.
We’re getting close!
Watching for Transcription .txt files
This brings us to our final piece of the puzzle. Now that we have a .txt transcription, a .json file containing the data and a .mp3 file laying on our computer, we can finally compile it all:

This automation constantly monitors that same special folder for any files to be added so as soon as Whisper Transcription is done creating the transcription, this automation triggers. It filters for only .txt files as a starting point, grabs the content from the .txt (the transcription), uses the filename of the .txt to grab the adjacent .json file (containing all the other information), glues it together to add the transcription to what was in the .json file, and finally executes the last workflow.
Summarize and post
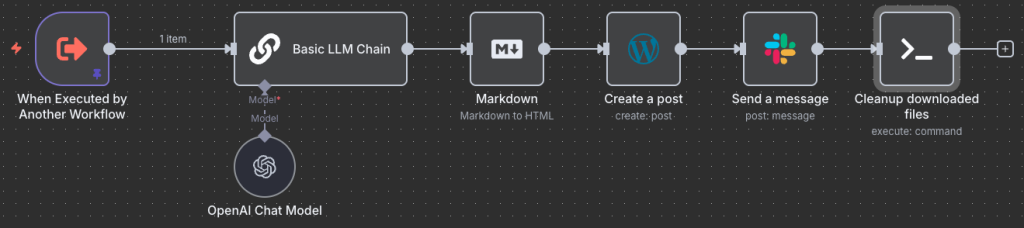
If you look back at “Sermon Summary Webhook” above, you’ll note that if there were already a transcription available we would have gone straight here. If we had a transcript initially from North Hills, we would have come straight here.
So now that we have all the metadata and transcription compiled, it’s time to do the AI magic.
We feed the transcription to the AI with a simple system prompt:
This is sermon transcription. Summarize the main points that were presented. Provide a summary of the action or application points put forward.
Only present information that is contained within the text, do not add to what is said in any way.
Do not provide a disclaimer or introduction, just what was asked.I use a locally hosted AI model google/gemma-3-12b to do this summary running on LM Studio on that same Mac Mini mentioned earlier.
This summary is pushed through a Markown to HTML converter block. LLMs love formatting in markdown, but wordpress doesn’t like markdown. This output and the metadata provided to the workflow are used to generate a post on my wordpress site.
The resulting post is sent to me via Slack to review and start reading myself.
The last “cleanup downloaded files” command deletes the files we compiled if present (the .txt, .json and .mp3 files used).
Kicking off the process
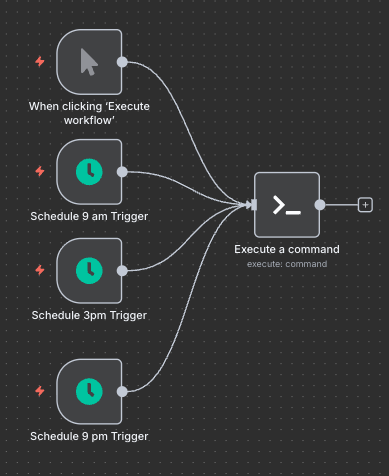
We do have one last bit of homework, and that is scheduling running the puppeteer command so that I can have all this work done for me. I was not exactly sure when the content and transcripts go up after the sermon on Sunday, so I guessed at some times: 9am, 3pm and 9pm on Sunday, Monday and Tuesday. That’s a total of 9 times over 3 days I’d scrape the site so it’s not just constantly causing traffic to the site.